
 大数据经典论文解读Bigtable(二):不认识“主人”的分布式架构 Bigtable(三):SSTable存储引擎详解 Bigtable(一):错失百亿的Friendster Borg(二):互不“信任”的调度系统 Borg(一):当电力成为成本瓶颈 Dataflow(二):MillWheel,一个早期实现 Dataflow(三):一个统一的编程模型 Dataflow(一):正确性、容错和时间窗口 Hive:来来去去的DSL,永生不死的SQL Kafka(二):从Lambda到Kappa,流批一体计算的起源 Kafka(一):消息队列的新标准 MapReduce(二):不怕失败的计算框架 MapReduce(一):源起Unix的设计思想 Megastore(二):把Bigtable玩出花来 Megastore(三):让Paxos跨越“国界” Megastore(一):全国各地都能写入的数据库 Raft(二):服务器增减的“自举”实现 Raft(一):不会背叛的信使 Spanner(二):时间的悖论 Spanner(三):严格串行化的分布式系统 Spanner(上):“重写”Bigtable和Megastore Spark:别忘了内存比磁盘快多少 TheGoogleFileSystem(二):如何应对网络瓶颈? TheGoogleFileSystem(三):多写几次也没关系 TheGoogleFileSystem(一):Master的三个身份 从Dremel到Parquet(二):他山之石的MPP数据库 从Dremel到Parquet(一):深入剖析列式存储 从Omega到Kubernetes:哺育云原生的开源项目 从S4到Storm(二):位运算是个好东西 从S4到Storm(一):当分布式遇上实时计算 当数据遇上AI,Twitter的数据挖掘实战(二) 当数据遇上AI,Twitter的数据挖掘实战(一) 分布式锁Chubby(二):众口铄金的真相 分布式锁Chubby(三):移形换影保障高可用 分布式锁Chubby(一):交易之前先签合同 十年一梦,一起来看Facebook的数据仓库变迁(二) 十年一梦,一起来看Facebook的数据仓库变迁(一) 通过Thrift序列化:我们要预知未来才能向后兼容吗?
大数据经典论文解读Bigtable(二):不认识“主人”的分布式架构 Bigtable(三):SSTable存储引擎详解 Bigtable(一):错失百亿的Friendster Borg(二):互不“信任”的调度系统 Borg(一):当电力成为成本瓶颈 Dataflow(二):MillWheel,一个早期实现 Dataflow(三):一个统一的编程模型 Dataflow(一):正确性、容错和时间窗口 Hive:来来去去的DSL,永生不死的SQL Kafka(二):从Lambda到Kappa,流批一体计算的起源 Kafka(一):消息队列的新标准 MapReduce(二):不怕失败的计算框架 MapReduce(一):源起Unix的设计思想 Megastore(二):把Bigtable玩出花来 Megastore(三):让Paxos跨越“国界” Megastore(一):全国各地都能写入的数据库 Raft(二):服务器增减的“自举”实现 Raft(一):不会背叛的信使 Spanner(二):时间的悖论 Spanner(三):严格串行化的分布式系统 Spanner(上):“重写”Bigtable和Megastore Spark:别忘了内存比磁盘快多少 TheGoogleFileSystem(二):如何应对网络瓶颈? TheGoogleFileSystem(三):多写几次也没关系 TheGoogleFileSystem(一):Master的三个身份 从Dremel到Parquet(二):他山之石的MPP数据库 从Dremel到Parquet(一):深入剖析列式存储 从Omega到Kubernetes:哺育云原生的开源项目 从S4到Storm(二):位运算是个好东西 从S4到Storm(一):当分布式遇上实时计算 当数据遇上AI,Twitter的数据挖掘实战(二) 当数据遇上AI,Twitter的数据挖掘实战(一) 分布式锁Chubby(二):众口铄金的真相 分布式锁Chubby(三):移形换影保障高可用 分布式锁Chubby(一):交易之前先签合同 十年一梦,一起来看Facebook的数据仓库变迁(二) 十年一梦,一起来看Facebook的数据仓库变迁(一) 通过Thrift序列化:我们要预知未来才能向后兼容吗? 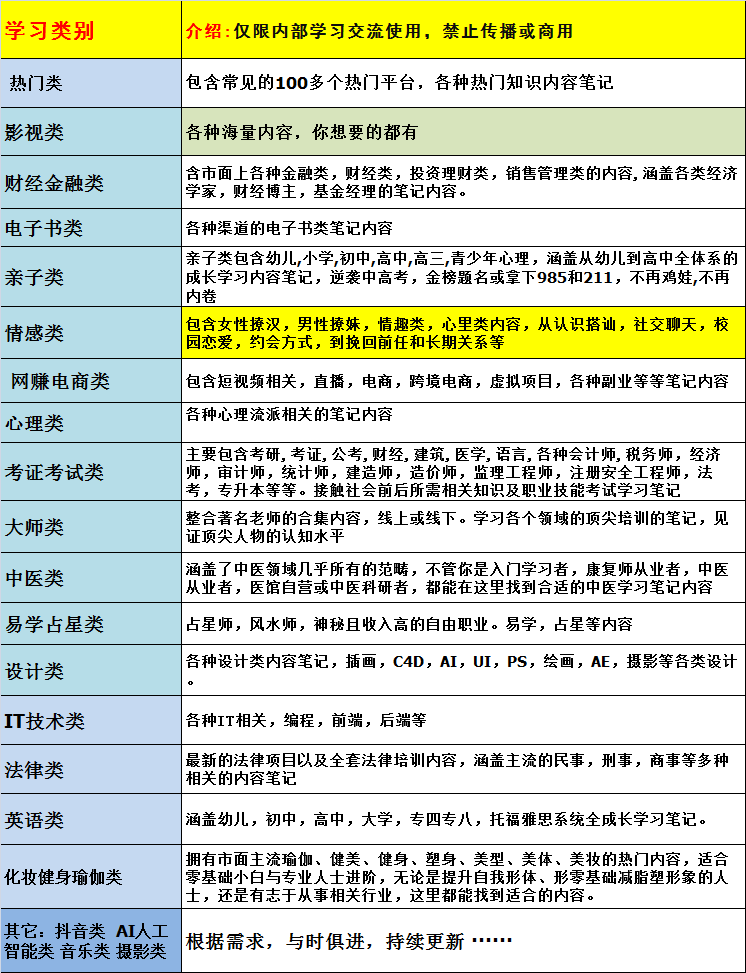
声明:本站大部分资源来源于网络,除本站组织的资源外,版权归原作者所有,如有侵犯版权,请立刻和本站联系并提供证据,本站将在三个工作日内改正。 本站仅提供学习的平台,将不对任何资源负法律责任,只作为购买原版的参考,并无法代替原版,所有资源请在下载后24小时内删除;资源版权归作者所有,如果您觉得满意,请购买正版。您若发现本站侵犯了你的版权利益,请来信本站将立即予以删除!














